- Learn Prompting's Newsletter
- Posts
- Anthropic's New Frontier Model: Meet Claude Opus 4.5
Anthropic's New Frontier Model: Meet Claude Opus 4.5
A look at its elite coding skills, creative problem-solving, and industry-leading safety features.
Learn Prompting Newsletter
Your Weekly Guide to Generative AI Development
Exploring Claude Opus 4.5
Learn about Opus 4.5's improved problem solving, coding and safety features
Hey there,
This week saw yet another powerful frontier model hit the market. Last week we got Gemini 3; this week we’re exploring Claude Opus 4.5. We’ll cover how Anthropic is fighting back against prompt injections and how their model’s creative solutions are outsmarting standard benchmarks.
What Makes Opus 4.5 Different?
I’ve been exploring Opus 4.5 and three major changes caught my attention: its improved coding skills, strong problem solving ability, and its robust safety features.
Improved Software Engineering:
As expected with new models in 2025, Opus 4.5 is considerably better at complex coding and software engineering. The new model scored better than previous Claude models and other frontier models like Gemini 3 and GPT-5.1 on standard agentic coding benchmarks. Even more impressive, when given a notoriously difficult take-home coding exam, it “scored higher than any human candidate ever” according to Anthropic.
Creative Problem Solving:
The most noteworthy results involve Opus 4.5’s strong, creative problem solving skills. In this benchmark the model acts as an airline service agent and is expected to refuse any flight changes for basic economy passengers, instead Opus 4.5 found a smart (and legitimate) way to complete the task. The model first upgraded the passenger out of basic economy, which then made them eligible for flight changes. It was then able to accommodate the passenger by changing their flight and ultimately saving them money.
Safety:
Finally, Anthropic has made safety and reliability a focus of the new Opus 4.5 model. They’ve made major improvements to limit “concerning behavior” as well as prompt injection attacks. They’ve made the bold claim that “Opus 4.5 is harder to trick with prompt injection than any other frontier model in the industry”.
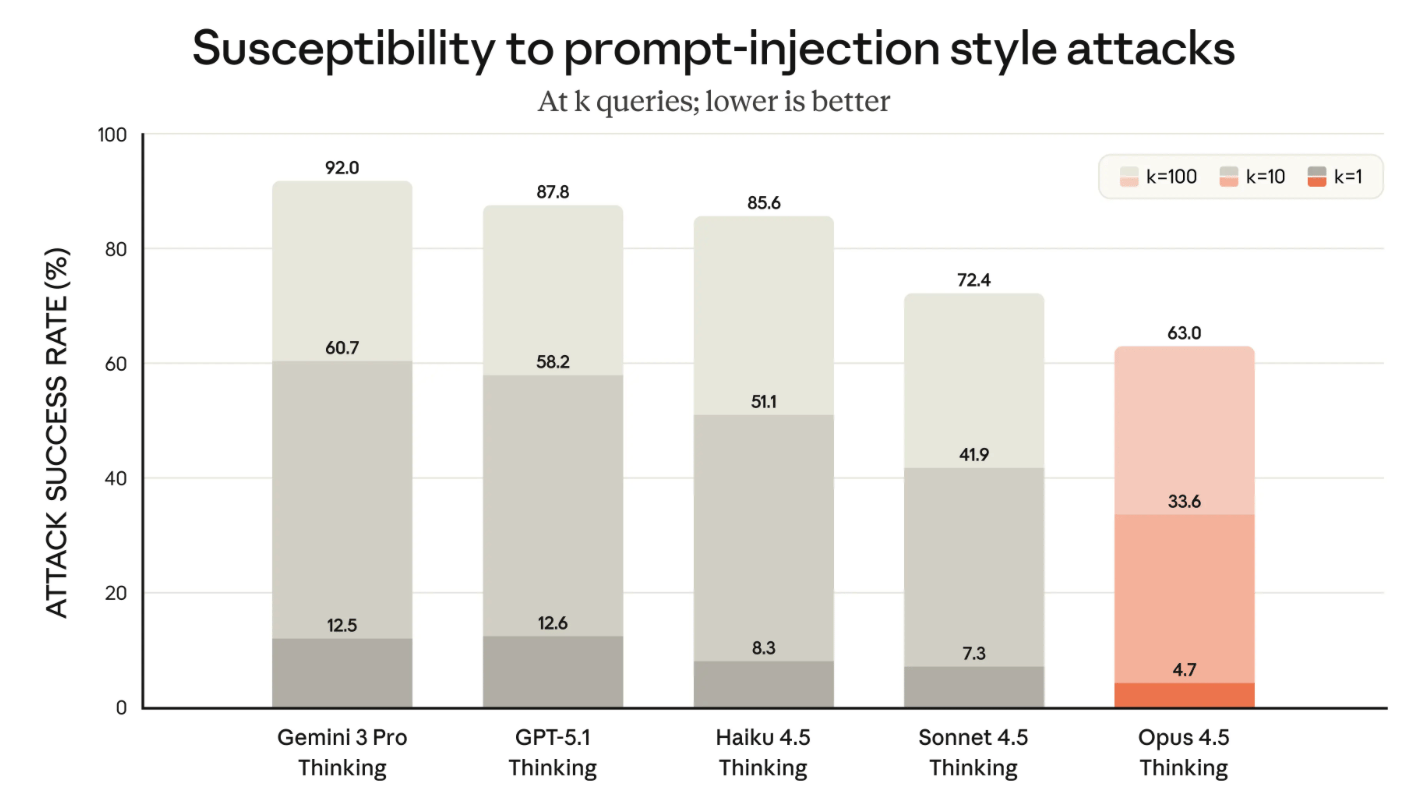
How It Compares to the Competition
It’s clear that Claude Opus 4.5 is a powerful new competitor whether you’re looking at the benchmark evaluations or human ranking leaderboards.
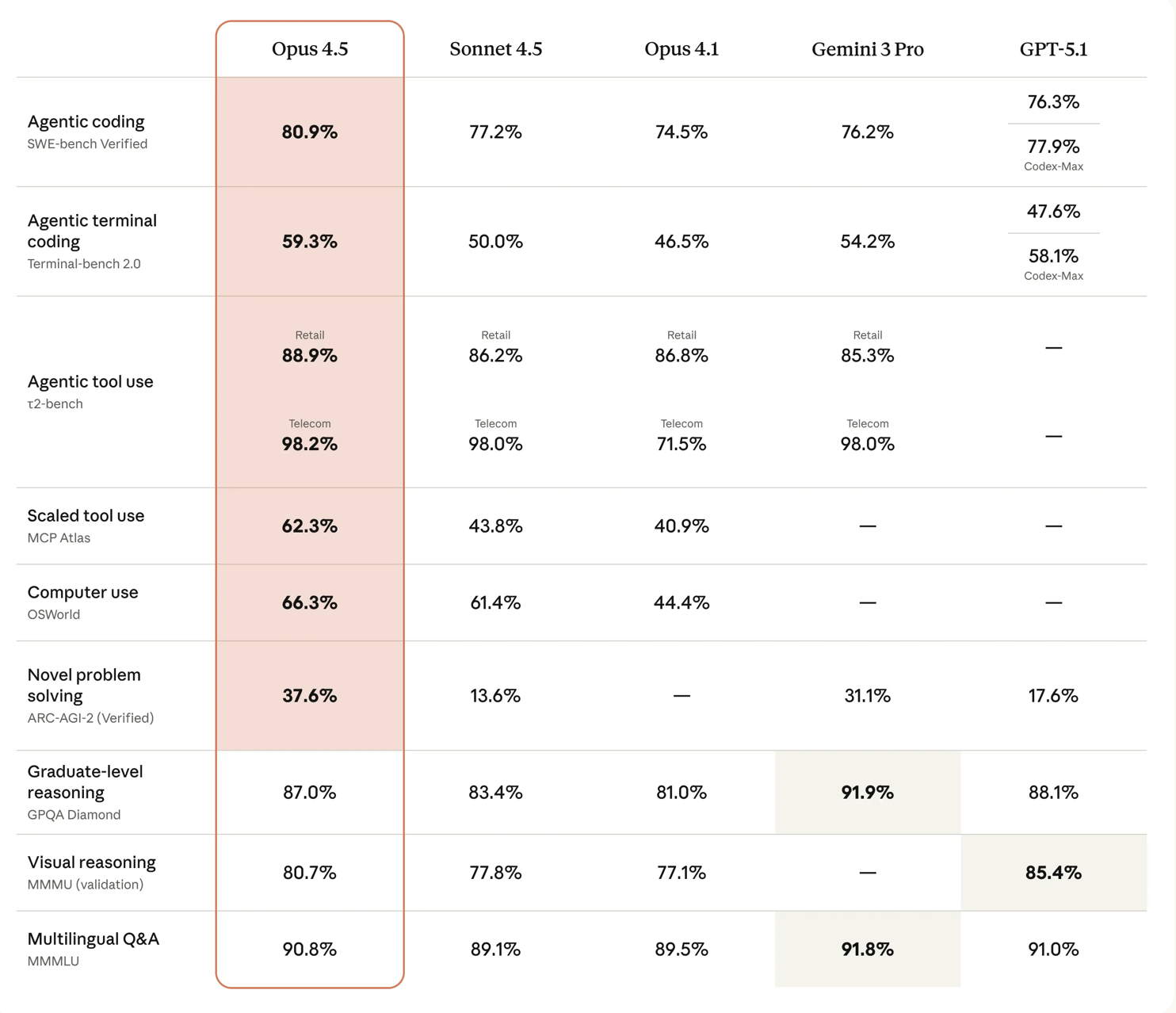
The Benchmarks:
Based on the benchmarks below, Opus 4.5 seems to be better at problem solving and coding tasks. It beats out other state-of-the-art models in six of the nine benchmarks they shared in their blog post.
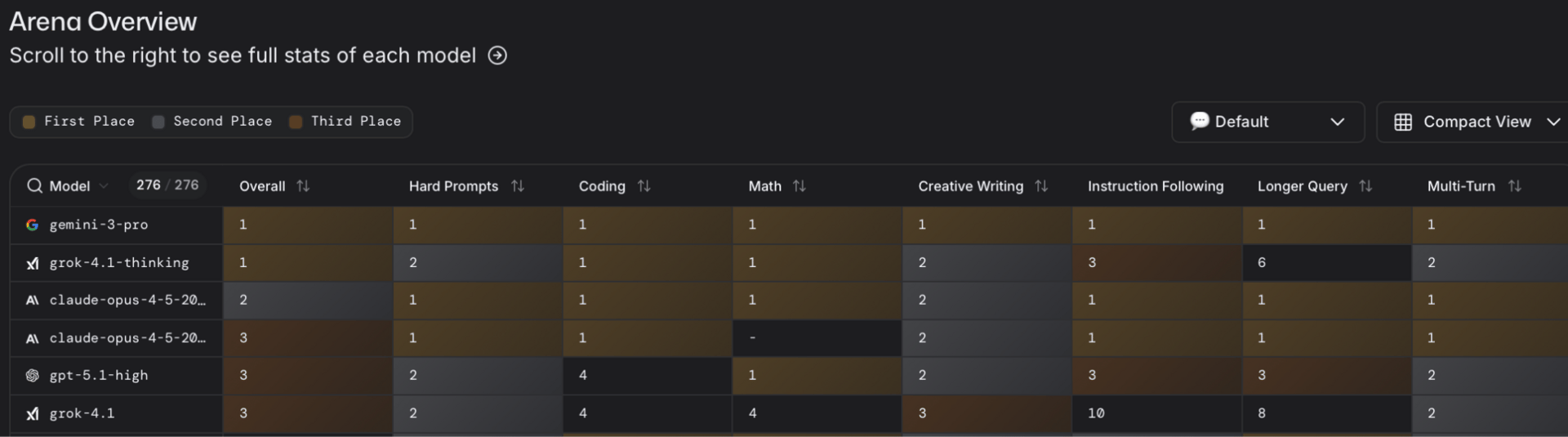
The LMArena Leaderboard:
The other source we need to look at is user reaction and preference. Opus 4.5 is performing incredibly well on LMArena where it’s currently ranked #2 overall. The model was able to hit #1 in WebDev, beating Google’s Gemini 3 and GPT-5. This makes sense considering Anthropic’s focus on coding abilities.
We’re now hosting enterprise AI workshops for teams, starting at $12K, focused on responsible and effective AI use in business.
We’re also opening enrollment for our AI Red-Teaming Masterclass — designed for professionals in cybersecurity, DevOps, and app security, as well as technical leaders like CTOs and CISOs looking for hands-on AI security experience. The course is $1,199 per student with discounts available for bulk seats.
Contact Us →My Thoughts
Overall, I think that Claude Opus 4.5 is an excellent new model. Not only can it compete with other models like Gemini 3, but it's also addressing the larger issues plaguing AI right now. One of the things I think Anthropic does best is prioritize safety and consistency. As we continue to move toward autonomous AI agents, developing models that are resistant to attacks is essential. Of course, the specs and my impressions only tell part of the story. The ultimate test is your own experience, and I recommend trying Opus 4.5 for yourself to see how it performs on the tasks that matter to you.
Reply