- Learn Prompting's Newsletter
- Posts
- The Best Way to Judge an AI Model
The Best Way to Judge an AI Model
A deep dive into LMArena, the crowdsourced leaderboard that reveals which models truly perform best.
Learn Prompting Newsletter
Your Weekly Guide to Generative AI Development
The Best Way to Judge an AI Model
A deep dive into LMArena, the crowdsourced leaderboard that reveals which models truly perform best.
Hey there,
Every time a new AI model drops, companies love to share cherrypicked evals showing their model beating the competition. This often leads to inflated expectations and confusion around what the evals really mean. This doesn’t even consider that many everyday AI users can’t fully appreciate what the evals show. So, in a world where every new model claims to be #1, how can you actually measure how models compare to each other? For me the answer is LMArena.
LMArena: The "Blind Taste Test" for AI
Many people (myself included) have favorite AI models or platforms that they choose to use regardless of how it compares to other models. Because of this, it can be hard to give unbiased opinions about new models. This is where the genius of LMArena comes in. By giving users a simple and easy way to blindly compare models, you can determine which model works best for you.
The Core Mechanic: Comparing Responses
LMArena works just like any other chatbot with one major twist, after you enter your prompt you’ll get two responses instead of one. You’ll then be asked to rate the responses.
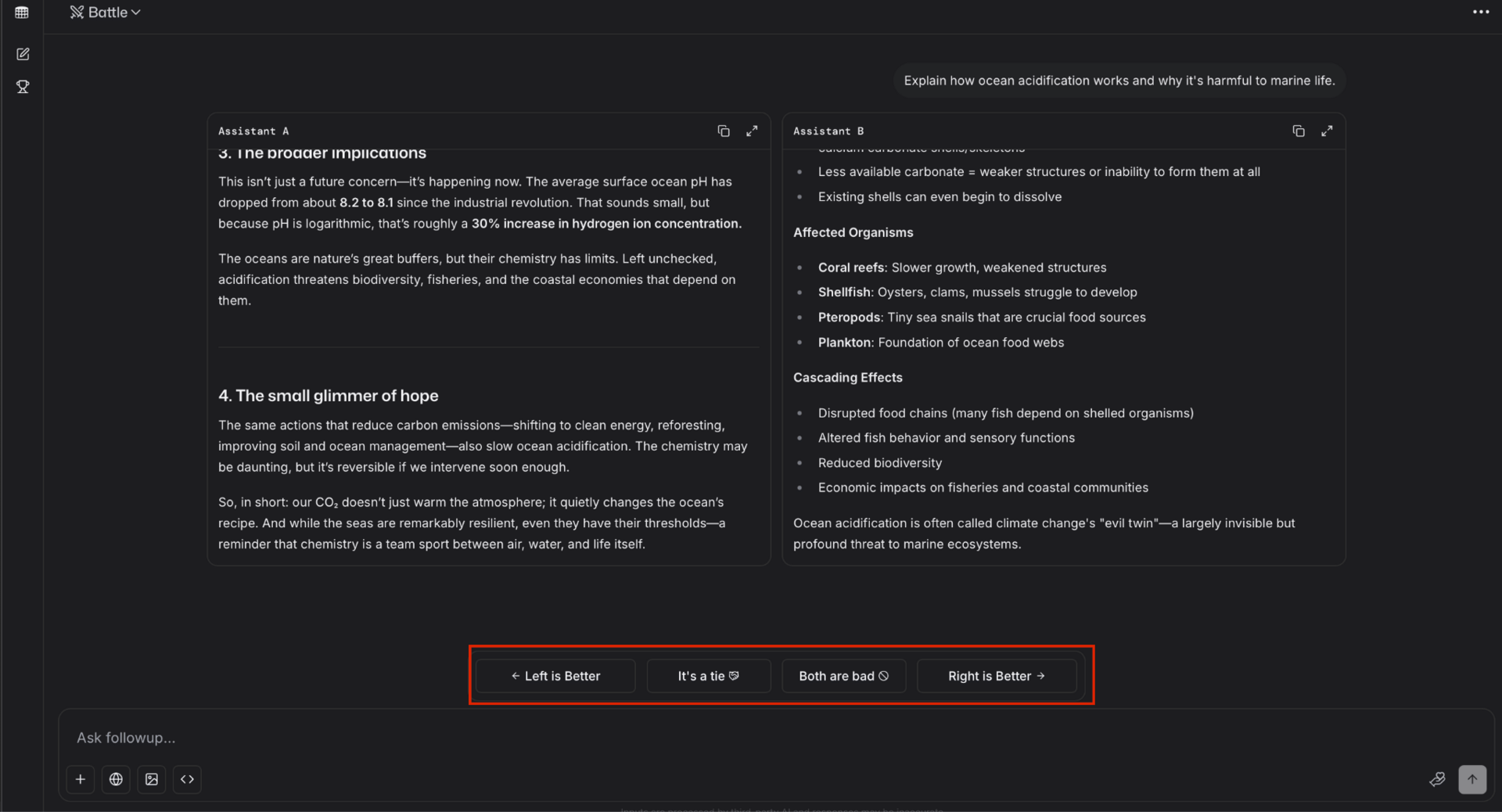
LMArena lets you vote for your preferred response.
After you select your preferred answer, LMArena shows the model names.
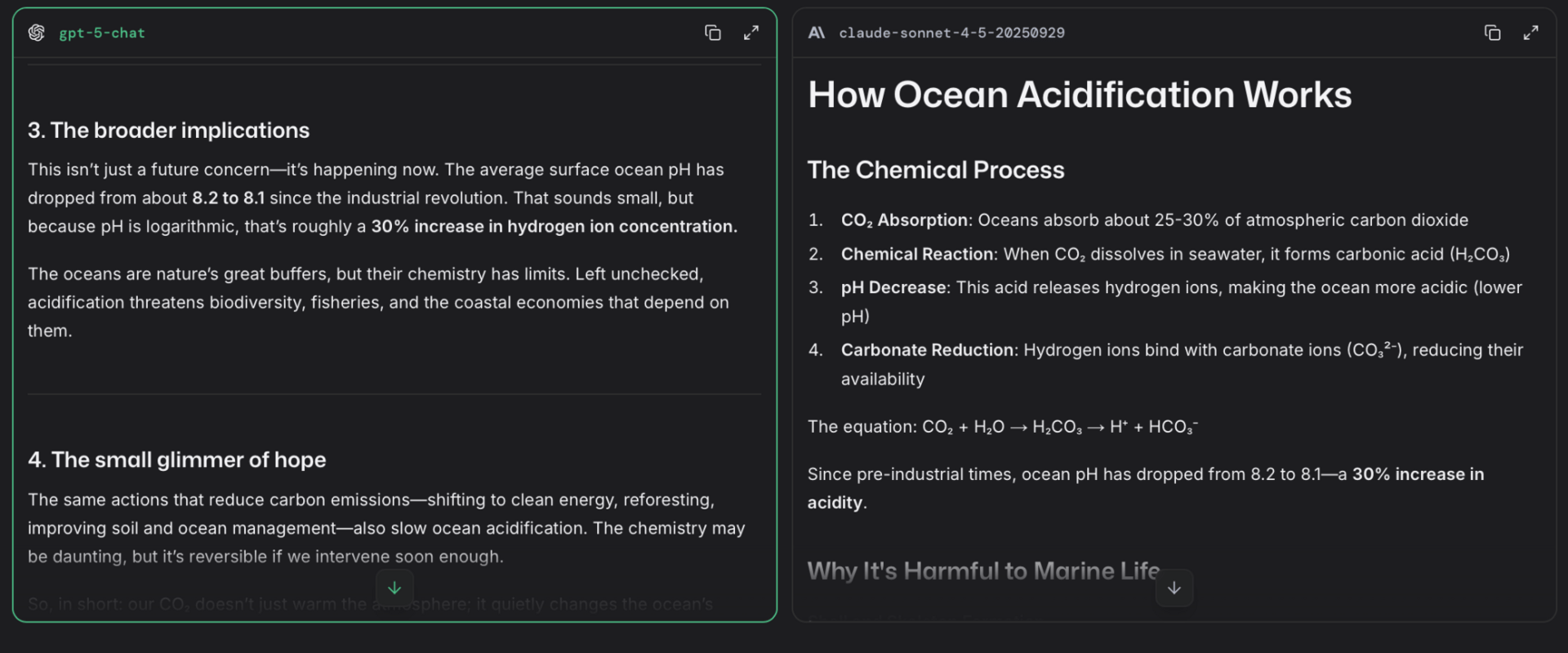
Being able to see the structural differences in responses is incredibly useful.
You can keep the chat going even after the first response as each prompt will generate two new responses.
The Leaderboards
After thousands of users cast their votes, LMArena uses an Elo rating system to rank each model. This creates a fluid, merit-based leaderboard where real-world preferences determine which model is ranked #1. It serves as a great resource for developers looking for specific model capabilities and real-world testing.
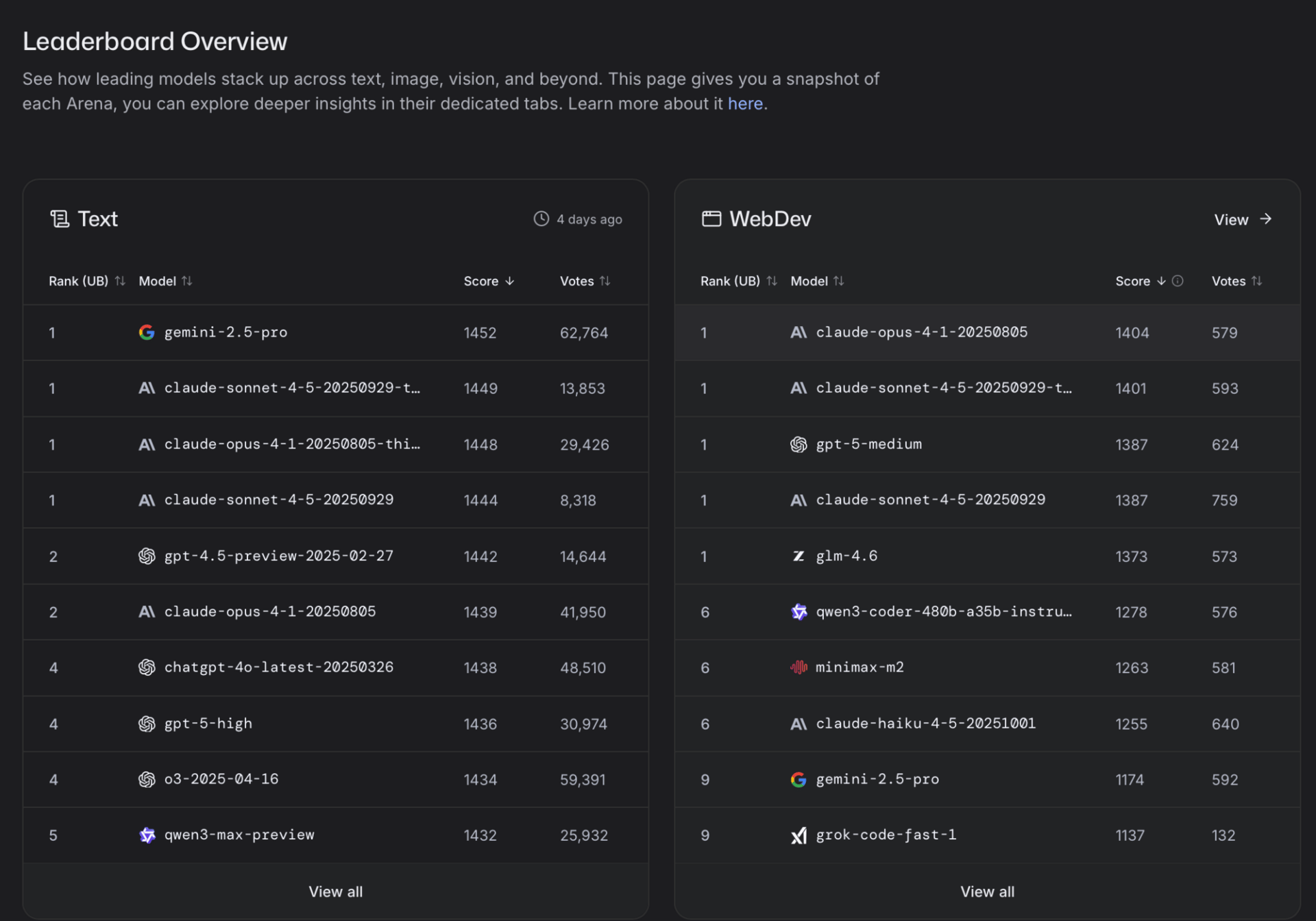
LMArena allows models to tie when their Elo scores are close.
Why This is Better Than Benchmarks (For Most People)
While benchmarks have their place, they often leave an incomplete picture of a model. It's great to know that one model is 5% better at math, but how does that manifest in daily use? Can most users even tell the difference?
LMArena is so valuable because it moves past the technical specs and shows how models perform in real, everyday scenarios. It measures the things that are hard to quantify but easy to feel. Is the model’s tone helpful? Does it push back and give genuine feedback? But more importantly, it shows how users feel about this behavior. It ultimately measures user preference.
The other important advantage is that the leaderboards are always up-to-date. A benchmark eval is a static snapshot that can be outdated in weeks or even days, while LMArena provides a real-time look at the current AI models.
We’re now hosting enterprise AI workshops for teams, starting at $12K, focused on responsible and effective AI use in business.
We’re also opening enrollment for our AI Red-Teaming Masterclass — designed for professionals in cybersecurity, DevOps, and app security, as well as technical leaders like CTOs and CISOs looking for hands-on AI security experience. The course is $1,199 per student with discounts available for bulk seats.
Contact Us →My Thoughts:
For me LMArena is a definitive part of judging a model’s performance. While I do look at (and share) benchmarks, I always make sure to see how users are reacting to a model. And while I don’t have any current AI-powered projects online at the moment, being able to easily test and compare models without needing API keys or paid accounts is incredibly helpful.
All that being said, LMArena isn’t perfect. Judging AI responses is a highly personalized experience and you may value certain model behavior more than others. I’d recommend using LMArena as an additional metric when evaluating a model’s performance.
Ultimately, LMArena serves as a crucial check on the excessive hype that surrounds model releases. It encourages us to look past the dazzling benchmarks and instead focus on a more important metric: real-world performance and genuine user preference.
The best way to understand LMArena is to try it yourself. Go cast some votes and see which models you prefer. You might be surprised by the results!
Try LMArena →
Reply